서로 다른 차원의 numpy끼리 연산하는 방법인 broadcasting의 개념에 대해 소개합니다.
브로드캐스팅
-
기본적으로 numpy의 연산은 Shape이 같은 두 ndarray에 대한 연산만이 가능하다.
-
하지만, 서로 Shape이 다른 numpy끼리도 연산이 가능한 경우가 있다. 이를 브로드 캐스팅(Shape을 맞춤)이라 한다.
브로드캐스팅 Rule
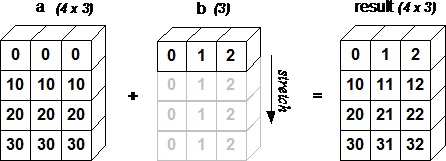
1
| - 출처: https://www.tutorialspoint.com/numpy/images/array.jpg
|
Shape이 같은 경우의 연산
1
2
3
4
| x = np.arange(15).reshape(3, 5)
y = np.random.rand(15).reshape(3, 5)
print("x:\n",x,"\n")
print("y:\n",y)
|
x:
[[ 0 1 2 3 4]
[ 5 6 7 8 9]
[10 11 12 13 14]]
y:
[[0.09750476 0.03329158 0.4588553 0.41886341 0.88091397]
[0.05444735 0.49626685 0.07778171 0.71429232 0.0817233 ]
[0.6663016 0.07144051 0.39546019 0.573171 0.06219814]]
1
2
| # 각 index가 매칭되는 값들끼리 더해서 동일한 shape의 행렬이 나온다.
x + y
|
array([[ 0.09750476, 1.03329158, 2.4588553 , 3.41886341, 4.88091397],
[ 5.05444735, 6.49626685, 7.07778171, 8.71429232, 9.0817233 ],
[10.6663016 , 11.07144051, 12.39546019, 13.573171 , 14.06219814]])
array([[0. , 0.03329158, 0.91771061, 1.25659024, 3.52365589],
[0.27223674, 2.97760112, 0.544472 , 5.71433857, 0.7355097 ],
[6.66301595, 0.78584561, 4.74552231, 7.45122304, 0.87077392]])
Scalar(상수)와의 연산
1
2
| # 상수는 어떠한 shape의 numpy라도 연산이 가능
x + 2
|
array([[ 2, 3, 4, 5, 6],
[ 7, 8, 9, 10, 11],
[12, 13, 14, 15, 16]])
array([[ 0, 2, 4, 6, 8],
[10, 12, 14, 16, 18],
[20, 22, 24, 26, 28]])
array([[ 0, 1, 4, 9, 16],
[ 25, 36, 49, 64, 81],
[100, 121, 144, 169, 196]], dtype=int32)
array([[ True, False, True, False, True],
[False, True, False, True, False],
[ True, False, True, False, True]])
Shape이 다른 경우 연산
1
2
3
4
5
6
7
| a = np.arange(12).reshape(4, 3) # 4행 3열
print("a는\n:",a,"\n")
print("a의 shape는 :",a.shape,"\n")
b = np.arange(100, 103)
print("b는\n:",b,"\n")
print("b의 shape는 :",b.shape,"\n")
|
a는
: [[ 0 1 2]
[ 3 4 5]
[ 6 7 8]
[ 9 10 11]]
a의 shape는 : (4, 3)
b는
: [100 101 102]
b의 shape는 : (3,)
array([[100, 102, 104],
[103, 105, 107],
[106, 108, 110],
[109, 111, 113]])
1
2
3
4
5
6
7
| c = np.arange(1000, 1004)
print("c는\n:",c,"\n")
print("c의 shape는 :",c.shape,"\n")
d = b.reshape(1, 3)
print("d는\n:",d,"\n")
print("d의 shape는 :",d.shape)
|
c는
: [1000 1001 1002 1003]
c의 shape는 : (4,)
d는
: [[100 101 102]]
d의 shape는 : (1, 3)
1
2
| print("a의 shape는 :",a.shape,"\n")
print("c의 shape는 :",c.shape,"\n")
|
a의 shape는 : (4, 3)
c의 shape는 : (4,)
array([[100, 102, 104],
[103, 105, 107],
[106, 108, 110],
[109, 111, 113]])
1
2
| print("a의 shape는 :",a.shape,"\n")
print("d의 shape는 :",d.shape)
|
a의 shape는 : (4, 3)
d의 shape는 : (1, 3)





댓글남기기