
🚦Summary
Transformer 부터 CLIP, MAMBA 까지 CV, NLP의 다양한 기초 논문부터 핫한 논문까지 아이펠 리서치 과정 그루들의 다양한 논문 리뷰!
📜 AIEFFL 7th 교류회 후기 📜
📌 Intro.
- 어느덧 6개월이라는 AIFFEL 교육기간중 4개월이라는 시간이 지났습니다.
- 커리큘럼으로 정해진 교육은 모두 끝마쳤고 남은것은 아이펠톤을 통한 최종 포트폴리오를 만드는 것 뿐입니다.
- AIFFEL 온라인 코스에는 Core와 Research 라는 두 가지 커리큘럼이 있습니다.
- 사실 같은 기수라고는 하지만 커리큘럼이 다르다 보니 코어정과 리서치 과정이 교류할 일은 사실상 거의 없었습니다.
- 게다가 코어의 경우 교육과정에서 배운 다양한 알고리즘을 통한 실용적 기능을 구현해보고 활용하는 것, 그리고 이를 탑재하는 Flutter 앱 구축에 중점이 있다보니 상대적으로 AI 논문들을 접하고 딥하게 다뤄보는 것을 경험할 일이 개인적인 시도가 아니라면 거의 없습니다.
- 코어과정에 참여중인 저로서는 이번 교류회에서 크게 2가지 목적이 있었습니다.
- 첫째, 다양한 딥러닝 논문을 접하고 이해하는 과정에 대한 간접 경험
- 둘째, 최종 프로젝트인 아이펠톤에 적용할 아이템 발굴
- 다만, 처음 접하거나 알고 있던 내용들을 정리하는 것에 좀 더 초점을 두고 세미나를 참여했고, 이 내용들을 각 논문별로 핵심만 추려 최대한 간단히 정리해보았습니다.
Research 의 논문 리뷰
- 리서치 과정의 동기 그루분들이 커리큘럼과정에서 공부한 다양한 딥러닝 논문을 리뷰하며 논문의 내용들을 소개해주는 시간을 가졌습니다.
- 이번 교류회에서 살펴본 논문들은 크게 6 개였습니다.
- “Attention is all you need, 2017”
- “An Image is Worth 16x16 Words Transformers for Image Recognition at Scale, 2020”
- Learning Transferable Visual Models From Natural Language Supervision, 2021
- “Segment Anything, 2023”
- “Self-Attention Does Not Need O(n^2) Memory,2021”
- “Mamba Linear-Time Sequence Modeling with Selective State Spaces, 2023”
- 접해본 논문들도 있었지만, 완전히 처음보거나, 알고는 있었지만 원리에 대해서는 잘 알지 못하는 논문들도 있었습니다.
- 기초적인 논문에서도 가볍게 “그런가보다~” 하고 대충 이해하고 넘어간 것들을 다시 살펴보는 계기가 되었고, 전혀 처음 보는 논문들에 대해서도 관심을 갖게 되는 계기가 되는 자리였던 것 같습니다.
- 각 세션(논문)별로 주의 깊게 봤던 주요 내용들을 정리해 보았습니다.
- 다만, 각 세션별 발표 구성이 달라 내용의 흐름대로 정리하다보니 포멧이 일정하지 못합니다😅
Attention is all you need
“Attention is All You Need” 논문은 자연어 처리(NLP) 분야에 혁신적인 변화를 가져온 기념비적인 논문으로 유명합니다. 이 논문에서 제안 된 Transformer(Transformer) 모델은 RNN(Recurrent Neural Networks)과 CNN(Convolutional Neural Networks)에 의존하지 않고도 문장 내 단어 간의 관계를 효과적으로 학습할 수 있는 새로운 접근 방식을 소개하였습니다.

Scaled Dot-Production Attention 구조
- Scaled Dot-Product Attention
- 이 메커니즘은 쿼리(Query), 키(Key), 밸류(Value)의 세 가지 요소를 사용하여 입력 데이터의 각 단어가 다른 단어와 얼마나 관련이 있는지를 계산합니다. 스케일링 과정을 통해 Attention 메커니즘의 안정성을 높이며, 이는 Transformer 모델의 핵심적인 부분입니다.

Multi-Head Attention 수식
- Multi-Head Attention
- Multi-Head Attention은 입력 데이터에 대해 여러 개의 Attention 메커니즘을 병렬로 적용함으로써, 다양한 표현 공간에서 정보를 추출할 수 있습니다. 이를 통해 모델은 동일한 정보를 다양한 방식으로 해석하고, 입력 데이터의 복잡한 관계를 더 잘 이해할 수 있습니다.
- Positional Encoding
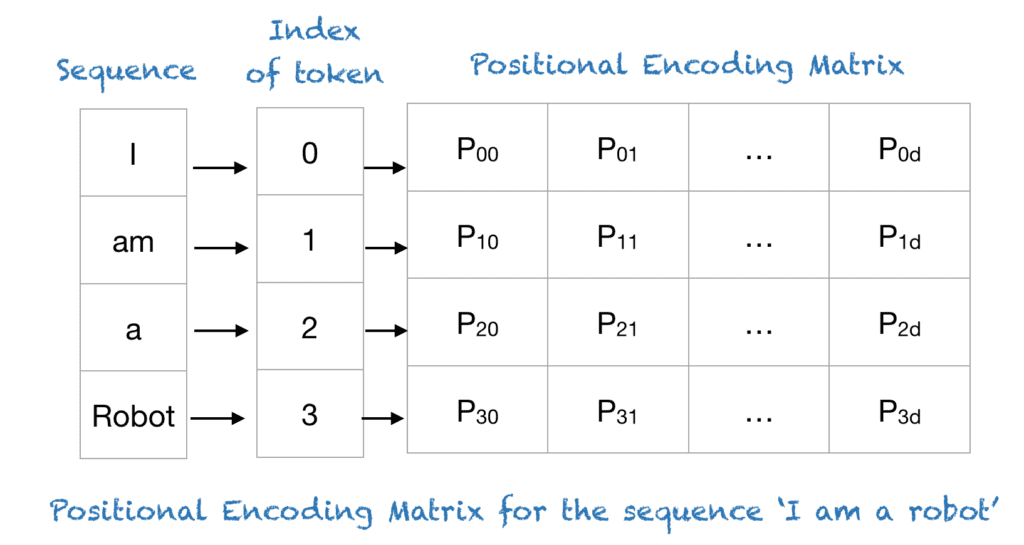
Positional Encoding 구조
-
Transformer
모델은 RNN이나 CNN과 달리 시퀀스의 순서 정보를 자동으로 학습할 수 없습니다. 이를 보완하기 위해 Positional Encoding을 도입하여 각 단어의 위치 정보를 모델에 제공합니다. 이는 시퀀스 내 단어의 순서를 모델이 인식할 수 있게 하며, 문장의 의미를 정확하게 파악하는 데 필수적입니다.
- 이 논문의 중요한 점은 기존의 시퀀스 처리 모델이 가지는 한계를 극복하고, 특히 긴 문장을 처리할 때 발생하는 정보 손실과 계산 효율성 문제를 해결한 것입니다. Transformer 모델은 Multi-Head Attention을 통해 문장 내 모든 단어 간의 관계를 한 번에 계산하므로, 병렬 처리가 가능해져 처리 속도가 매우 빨라집니다.
- 또한, Positional Encoding을 통해 단어의 순서 정보를 모델에 통합함으로써, 문장의 구조적 의미를 보다 정확하게 파악할 수 있게 되었습니다. 이러한 혁신적인 접근 방식은 Transformer 모델이 기계 번역, 텍스트 요약, 감정 분석 등 다양한 NLP 태스크에서 뛰어난 성능을 발휘할 수 있게 만들었습니다.
- “Attention is All You Need” 논문은 Transformer 모델을 통해 NLP 분야에 새로운 방향을 제시했습니다. 이 모델의 등장은 딥러닝 기반 자연어 처리 연구에 있어서 중요한 이정표가 되었으며, 이후 등장한 다양한 모델과 기술의 기반이 되었습니다. 특히, 이 모델을 기반으로 한 BERT, GPT와 같은 사전 학습된 언어 모델은 현재 NLP 연구와 응용의 최전선에서 활발히 사용되고 있습니다.
🤔 Q&A 에서 나온 흥미로운 내용들
질문 1 ‘임베딩’과 ‘인코딩’의 차이는 무엇인가요?
- 답변 ‘인코딩’은 정보를 일정한 규칙에 따라 다른 형태로 변환하는 과정을 의미합니다. 반면, ‘임베딩’은 데이터를 저차원 공간에 표현하기 위해 특정 레이어를 통해 학습되는 과정을 말합니다. 즉, ‘임베딩’은 데이터 간의 관계를 학습하여 고차원의 데이터를 저차원에서 의미 있게 표현하는 방식입니다. 인코딩은 변환 규칙이 사전에 정의되어 있지만, 임베딩은 데이터로부터 학습을 통해 표현 방식을 찾아냅니다.
질문 2 인코더와 디코더의 차이점은 무엇인가요?
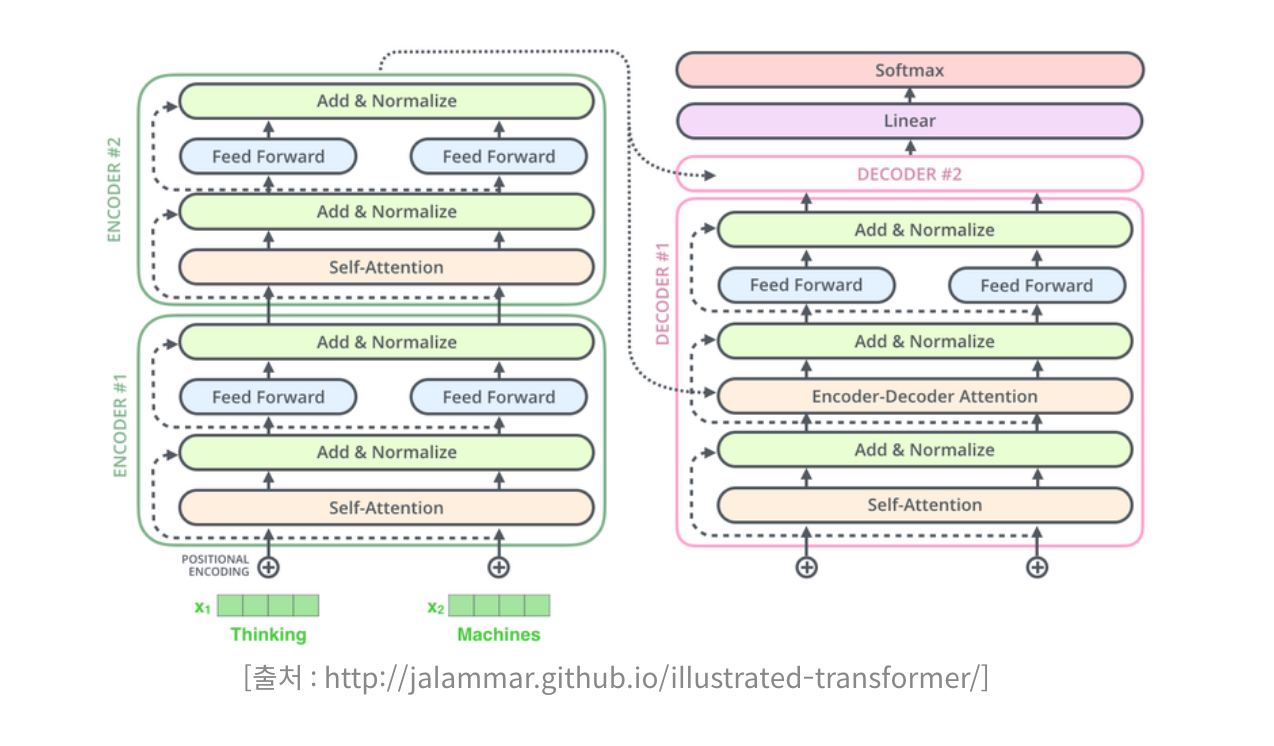
Transformer의 Encoder와 Decoder 구조
- 답변: 인코더는 입력 시퀀스를 고정된 크기의 벡터, 즉 컨텍스트 벡터로 변환하는 역할을 합니다. 이 과정에서 시퀀스의 정보를 압축하며, 주로 소스 언어의 문장을 내부적인 표현으로 변환하는 데 사용됩니다. 디코더는 이 컨텍스트 벡터를 사용하여 타겟 시퀀스를 생성합니다. 즉, 디코더는 인코더로부터 얻은 정보를 바탕으로 타겟 언어의 문장을 하나씩 생성해 나가는 역할을 합니다. 디코더는 이 과정에서 자기 자신의 이전 출력을 참조하여 다음 단어를 예측합니다.
ViT(Visual Transformer)
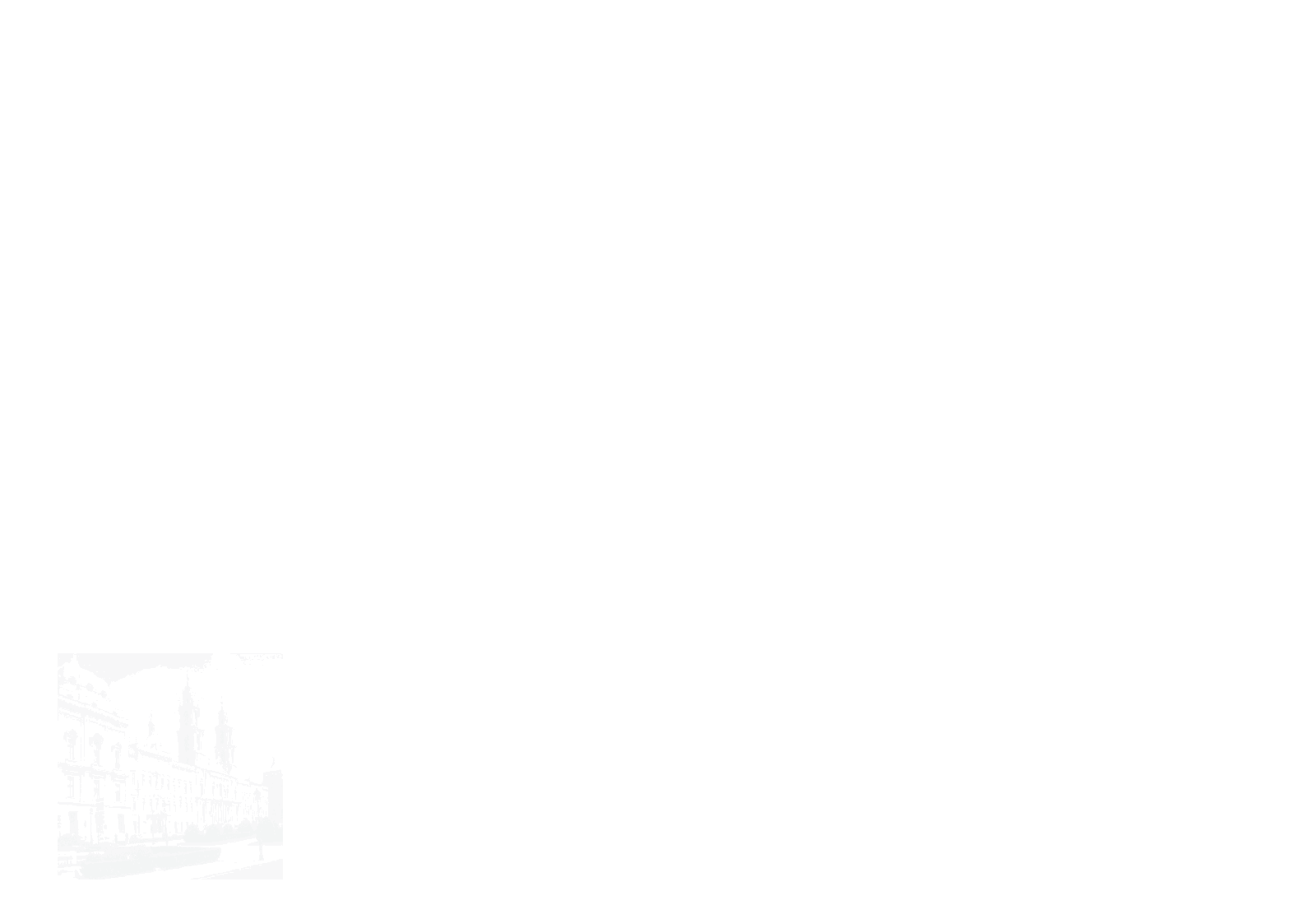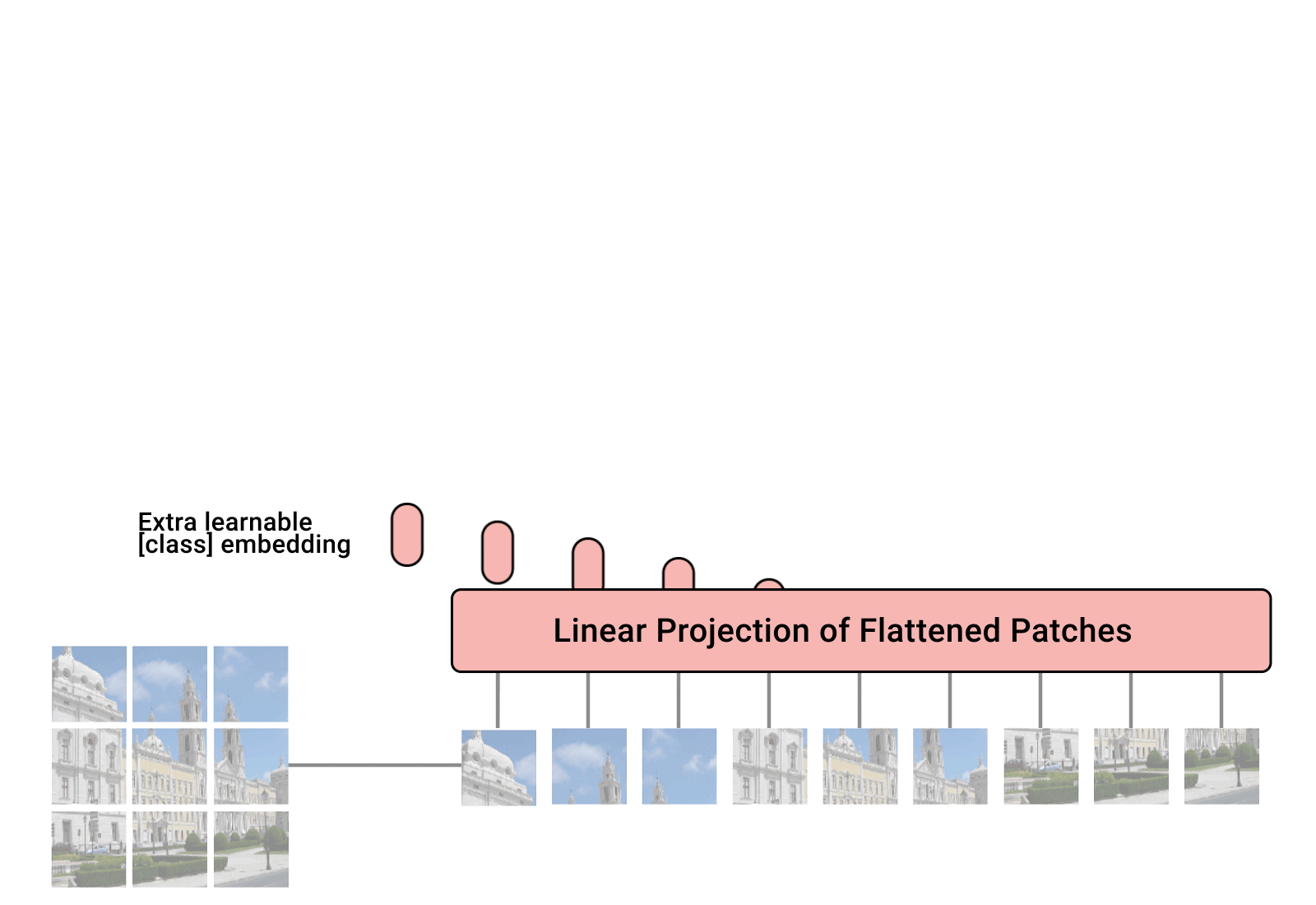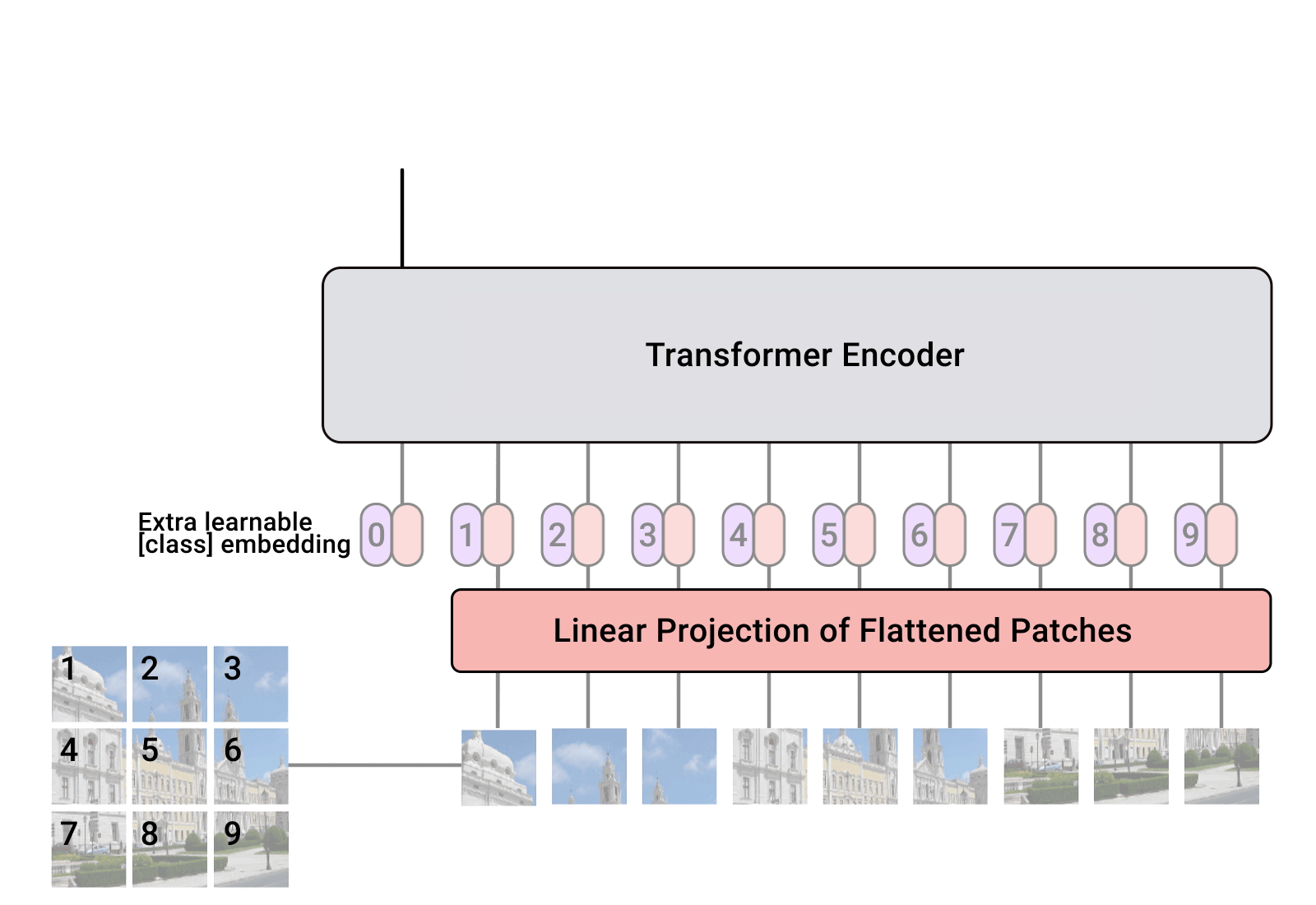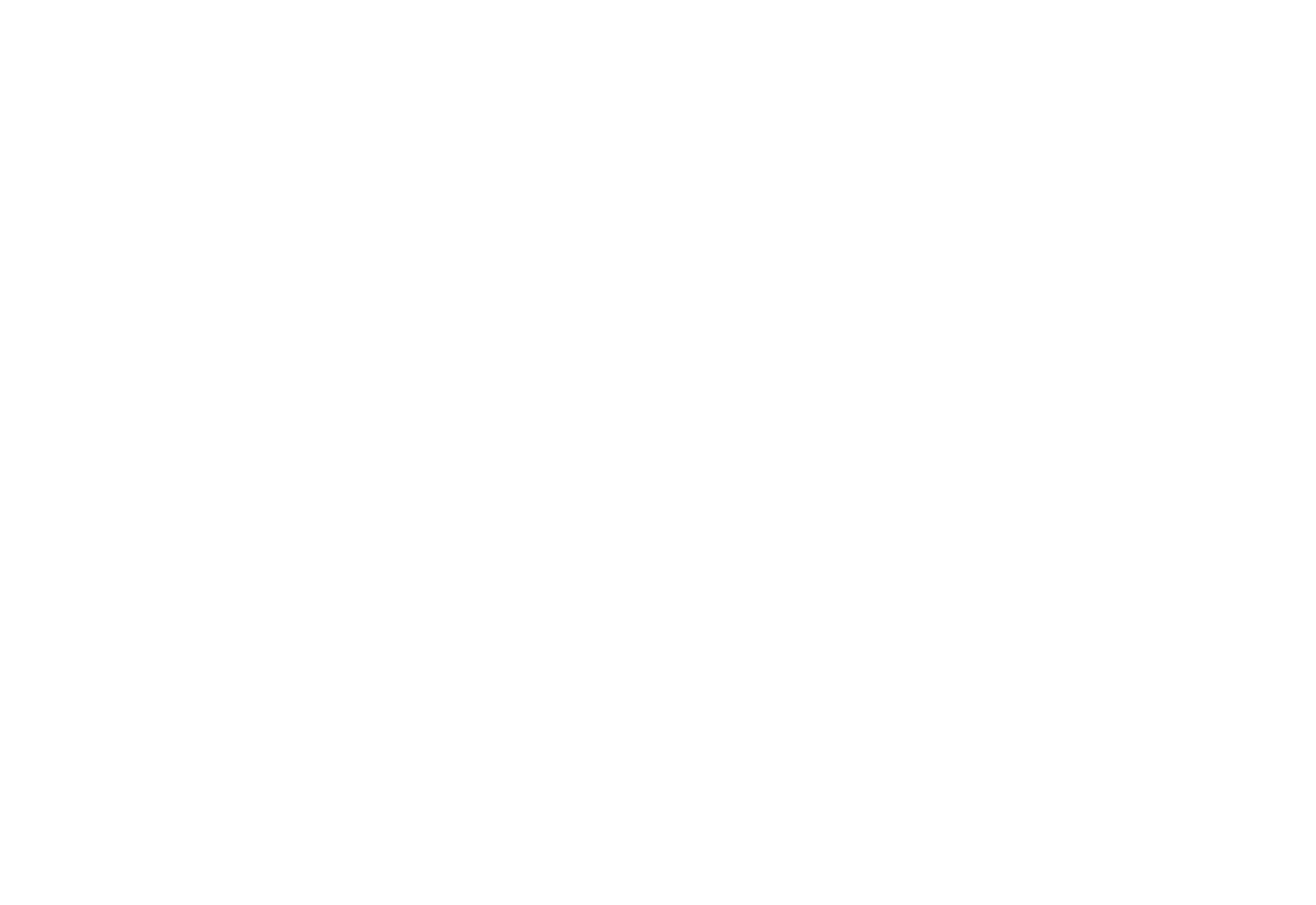
ViT Architecture
ViT(Vision Transformer)
ViT는 Transformer 아키텍처를 이미지 분류 작업에 적용한 것으로, “An Image is Worth 16x16 Words Transformers for Image Recognition at Scale” 논문에서 소개되었습니다. ViT는 이미지를 여러 개의 작은 패치로 나눈 후, 각 패치를 마치 단어(Word)처럼 취급하여 Transformer 모델의 입력으로 사용합니다. 이 과정에서 각 이미지 패치는 먼저 리니어 프로젝션을 통해 고정된 크기의 벡터로 변환되며, 이후 Transformer 인코더를 통과하면서 이미지 전체의 컨텍스트를 고려한 특성을 추출하게 됩니다.

CNN대비 ViT의 장점
되었습니다. 또한, ViT는 대규모 데이터셋에서 특히 뛰어난 성능을 보이며, ResNet과 같은 기존 CNN 모델들을 능가하는 결과를 보여주었습니다.
Inductive Bias와 ViT
ViT의 성공 요인 중 하나는 인덕티브 바이어스(Inductive Bias)의 감소입니다. CNN은 지역적인 특성을 강조하는 구조적 인덕티브 바이어스가 내재되어 있지만, ViT는 이러한 가정을 최소화합니다. 이는 ViT가 이미지의 글로벌한 특성을 더 자유롭게 학습할 수 있게 하며, 다양한 이미지 처리 작업에 더 유연하게 적용될 수 있는 기반을 마련해줍니다.
ViT의 한계와 도전 과제
ViT는 매우 유망한 결과를 보여주고 있음에도 불구하고, 여전히 해결해야 할 과제들이 있습니다. 예를 들어, 이미지의 고해상도 버전을 처리할 때의 계산 비용, 다양한 비전 작업으로의 확장 가능성, 자기지도 학습 방식의 최적화 등이 이 있습니다.
🤔 ViT에서 흥미로웠던 점
- ViT는 작은 부분의 특징을 분리하여 보는 것이 아니라 세부적으로 쪼개어 그 특징 간의 상관 관계를 파악하고 이를 결합하여 전체적인 global feature를 생성합니다.
- 이는 기존 모델들이 전체 이미지를 작은 부분으로 분리하여 각각의 특징을 독립적으로 고려하던 방식과는 대조적입니다.
- 그래서인지 "크게 보기 위해서 작은 것을 쌓아서 올리는 방식"으로 기존 모델들의 한계를 극복하면서도 새로운 시각을 제공한 점이 굉장히 획기적이라 느껴졌습니다.
- 어찌보면 ‘그간의 연구에서 집착하던 포인트를 놓아버림으로서 오히려 더 나은 결과를 얻은 격’ 이 아닌가 하는 생각이 들었습니다.
CLIP
- 개인적으로 가장 흥미롭게 본 논문 리뷰였습니다.
- 해당 기술을 응용해서 아이펠톤에서 앱 개발을 시도해보면 좋겠다는 생각을 했습니다.
- 구체적인 아이디어는 아직 구상 중이지만, 이 기술자체가 응용범위가 넓어서 다양한 부분에 응용이 가능할 것 같다 생각 했습니다.
- 특히, 대용량의 크롤링 데이터로 강건한 모델이라는 점이 그러한 확신을 갖게 해주었습니다.
CLIP은 OpenAI에 의해 개발된 혁신적인 딥러닝 모델로, 이미지와 자연어 설명 간의 관계를 이해하는 데 초점을 맞춥니다. 이 모델은 이미지 분류, 객체 탐지, 심지어 새로운 시각적 작업에 대한 제로샷(Zero-Shot) 학습 능력을 통해 주목을 받았습니다. 본 리뷰에서는 CLIP의 주요 개념, 아키텍처, 및 실제 적용 사례들에 대해 살펴보겠습니다.
CLIP의 기본 원리

CLIP 구조
CLIP은 대량의 이미지와 그에 해당하는 텍스트 설명을 이용해 학습합니다. 이 모델은 텍스트와 이미지 사이의 맥락적 유사성을 인코딩하여, 이미지에 대한 자연어 설명을 이해하고, 반대로 텍스트 설명에 맞는 이미지를 식별할 수 있습니다.
즉, CLIP은 텍스트 ↔️ 이미지 간 양방향 변화가 가능하며 이를 기반으로 다양한 응용 기술이 존재합니다. 이 것이 가능한 이유는 두 가지 유형의 데이터를 벡터화했을 때 이해할 수 있도록 이미지에 해당 하는 텍스트를 동시에 학습 했기 때문입니다.
아키텍처 설명
CLIP 모델은 두 가지 주요 구성 요소로 이루어져 있습니다. 첫 번째는 이미지 인코더로, 주로 Vision Transformer(ViT) 또는 ResNet과 같은 구조를 사용합니다. 두 번째 구성 요소는 텍스트 인코더로, Transformer 기반 모델을 사용해 텍스트 데이터를 처리합니다. 이 두 인코더는 각각의 모달리티에서 특징을 추출하며, 추출된 특징은 유사도 측정을 통해 서로 비교됩니다.
학습 방법
CLIP의 학습은 대조적 학습(Contrastive Learning) 방식을 통해 이루어집니다. 이는 긍정적인 샘플(정확하게 일치하는 이미지-텍스트 쌍)과 부정적인 샘플(일치하지 않는 쌍) 사이의 관계를 최적화하여 모델이 텍스트와 이미지 사이의 정확한 매칭을 학습하도록 합니다.
제로샷 학습 능력
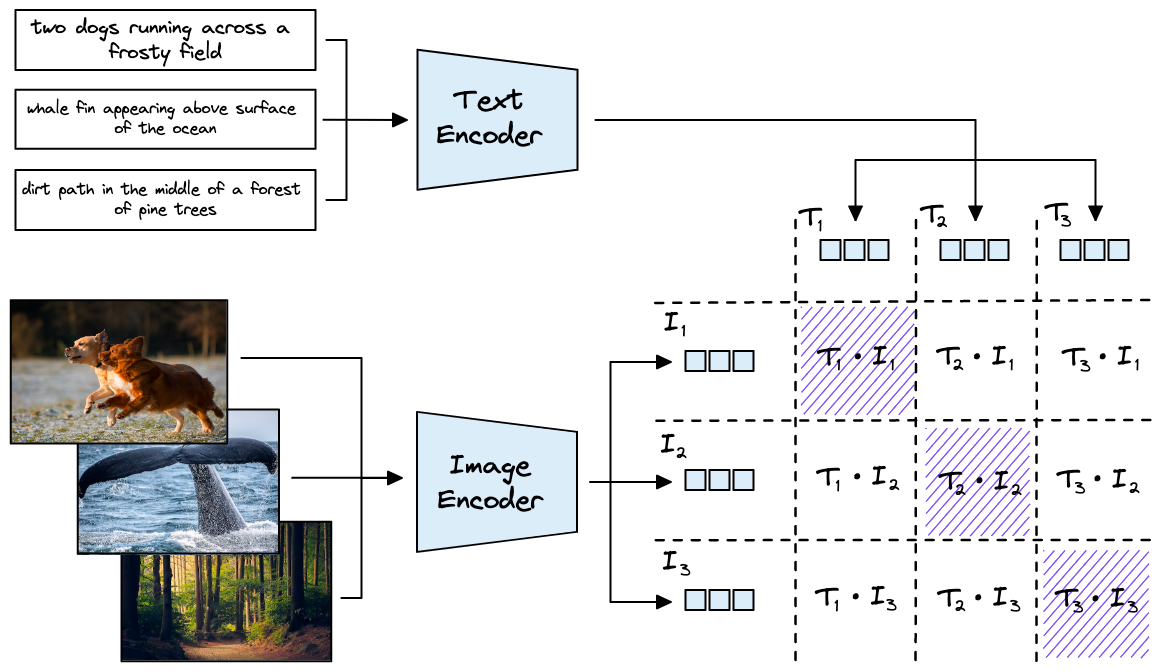
CLIP의 zero-shot 학습
학습 능력입니다. 이는 모델이 학습 과정에서 본 적 없는 새로운 카테고리의 이미지에 대해서도, 관련 텍스트 설명만을 바탕으로 정확한 분류를 수행할 수 있음을 의미합니다. 이러한 능력은 CLIP을 다양한 시각적 작업에 유연하게 적용할 수 있게 합니다.
실제 적용 사례
CLIP은 이미지 분류, 객체 탐지, 이미지 생성, 심지어 복잡한 시각적 질문 응답 시스템에 이르기까지 다양한 분야에서 활용됩니다. 특히, CLIP을 활용한 이미지 검색 시스템은 이미지에 대한 자연어 쿼리를 이해하고, 가장 관련성 높은 이미지를 반환하는 데 탁월한 성능을 보입니다.
- 텍스트 ➡️ 이미지 : 텍스트 설명을 입력하면 그에 맞는 이미지를 생성하거나 검색할 수 있습니다.
- 이미지 ➡️ 텍스트 : 이미지를 입력하면 그에 대한 자연어 설명을 생성할 수 있습니다.
결론
CLIP은 자연어 처리와 컴퓨터 비전을 융합한 독특한 접근 방식으로, 시각적 데이터와 자연어 사이의 깊은 상관관계를 이해합니다. 특히 제로샷 학습 능력은 별도의 학습 없이도 유연하게 다양한 서비스로 개발할 수 있는 기반을 제공합니다.
학습에 사용한 데이터 자체가 대규모의 다양한 클래스를 학습했기 때문에 이를 통해 유연한 추론이 가능합니다. 이러한 CLIP의 강점은 파인튜닝을 하고자 할때도 상대적으로 제한된 데이터로도 뛰어난 성능을 발휘할 수 있다는점 입니다.
도전 과제 및 발전 방향
다만, 아직 CLIP은 여전히 해결해야 할 도전 과제들이 존재합니다. 예를 들어, 모델의 해석 가능성과 편향 문제는 중요한 고려 사항입니다. 자연어 설명이 포함된 대규모 데이터셋을 사용함으로써, 데이터 내의 편향이 모델에 반영될 수 있으며, 이는 결과적으로 모델의 결정에 영향을 미칠 수 있습니다. 또한, CLIP의 성능은 데이터셋의 질과 양에 크게 의존하기 때문에, 고품질의 데이터 확보는 중요한 이슈로 남아있습니다.
SAM (Segment Anything)
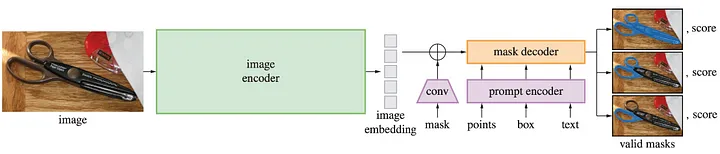
Segment Anything 모델 구조
- segmentation 기술은 컴퓨터 비전 분야에서 중요한 연구 주제 중 하나로, 이미지 내 개체를 정확하게 구분하고 이해하는 능력을 향상시키는 데 중점을 둡니다.
- 최근 SAM(Segmentation as a Model) 논문은 segmentation 문제에 대한 새로운 접근법을 제시하며, 이 분야에서 주목할 만한 진보를 이루었습니다.
SAM의 핵심 목표
1. 제로샷 일반화: SAM은 모델 학습 과정에서 어떠한 레이블 정보도 제공하지 않고도 다양한 이미지에 대한 segmentation 작업을 수행할 수 있도록 설계되었습니다. 이는 모델의 일반화 성능을 크게 향상시키는 중요한 요소입니다.
2. 프롬프트 기반 모델: SAM은 사용자가 제공하는 프롬프트(텍스트, 이미지, 마스크 등)를 기반으로 원하는 segmentation 결과를 도출합니다. 이는 모델의 유연성을 높이고 다양한 시나리오에 적용할 수 있도록 하는 핵심 기술입니다.
3. 효율적인 학습 및 추론: SAM은 데이터 엔진, 효율적인 훈련 방식, 실시간 추론 등을 통해 학습 및 추론 과정의 효율성을 크게 향상시켰습니다. 이는 모델의 실용성을 높이는 데 중요한 역할을 합니다.
SAM의 영향 및 기대 효과
1. segmentation 기술 발전: SAM은 segmentation 모델의 일반화 성능, 프롬프트 기반 segmentation, 효율적인 학습 및 추론 등을 통해 segmentation 기술의 발전에 크게 기여할 것으로 기대됩니다.
2. 다양한 분야: SAM은 의료 영상 분석, 자율주행, 로봇 비전, 스마트 시티 등 다양한 분야에 응용될 수 있으며, 이를 통해 컴퓨터 비전 기술의 발전과 사회 전반의 발전에 기여할 것으로 기대됩니다.
3. 연구 방향 제시: SAM은 segmentation 모델의 새로운 연구 방향을 제시하며, 향후 segmentation 기술의 발전에 중요한 역할을 할 것으로 기대됩니다.
SAM의 한계점 및 향후 과제
1. 모델 크기 및 계산 비용: SAM 모델은 기존 모델에 비해 크기가 크고 계산 비용이 높습니다. 향후 연구에서는 모델의 효율성을 더욱 향상 시키는 것이 중요합니다.
2. 모델 해석: SAM 모델은 블랙박스 모델로 작동하기 때문에 모델의 내부 작동 방식을 이해하기 어렵습니다. 향후 연구에서는 모델 해석 기술을 개발하여 모델의 신뢰성을 높이는 것이 필요합니다.
3. 데이터 편향: SAM 모델은 학습 데이터의 편향 영향을 받을 수 있습니다. 향후 연구에서는 데이터 편향 문제를 해결하고 모델의 공정성을 높이는 것이 중요합니다.
🤔 논문 리뷰 참여 후기
- 여러부분이 신기하긴 했지만 자연어처리의 프롬프트를 이미지 segmentation에 적용한 부분이 굉장히 인상깊었던 것 같습니다.
- 프롬프트를 통해 모델이 더 다양한 시나리오에 적용될 수 있다는 점이 차후에 다양한 분야에 CV기술을 적용할 수 있겠다는 생각이 들었습니다.
- 그리고 가능하다면 이러한 프롬프트 기반 segmentation 모델을 응용해서 아이펠톤에서 앱을 만들어 보는 것도 재밌겠다는 생각을 했습니다.
- 그리고, 기회가 된다면 ‘모델의 일반화 능력과 프롬프트의 다양성을 향상시키는 방법’ 에 대해서도 관련논문을 더 찾아보고 공부해보고 싶다는 생각이 들었습니다.
Self-Attention Does Not Need O(n^2) Memory
- 최근 딥러닝 연구에서는 모델의 성능을 향상시키기 위해 점점 더 크고 복잡한 모델을 사용하는 추세입니다. 하지만 이러한 모델들은 대량의 메모리를 소모하며, 특히 셀프 Attention(Self-Attention) 메커니즘이 포함된 모델은 시퀀스 길이에 따라 O(n^2)의 메모리를 필요로 합니다.
- 이는 긴 시퀀스 처리에 있어서 큰 제약으로 작용합니다. 하지만 최근 연구에서는 이러한 메모리 문제를 극복할 수 있는 새로운 방법을 제시하고 있습니다.
기존 셀프 Attention의 메모리 문제
- 셀프 Attention은 입력 시퀀스의 모든 요소들 사이의 상호작용을 모델링하여, 각 요소가 시퀀스 내 다른 요소들로부터 얼마나 많은 주의를 받을지 결정합니다.
- 이 과정에서 모든 요소 쌍 간의 상호작용을 계산하고 저장해야 하므로, 시퀀스 길이에 비례하여 제곱수로 메모리 사용량이 증가합니다.
메모리 효율적 알고리즘 소개
- 이 논문에서는 시퀀스 길이에 따라 고정된 양의 메모리만을 필요로 하거나, 최악의 경우에도 로그 함수에 비례하는 메모리만이 필요한 새로운 Attention 알고리즘을 제안합니다.
- 이는 메모리 사용량을 크게 줄이면서도 효율적으로 계산할 수 있게 함으로써, 긴 시퀀스를 처리할 때 발생하는 문제를 해결합니다.
알고리즘의 핵심 아이디어
- 제안된 알고리즘은 기존의 셀프 Attention과는 다르게, 소프트맥스 계산 과정에서 지수 함수의 합을 나중으로 미루는 ‘지연된 소프트맥스(Lazy Softmax)’ 기법을 사용합니다.
- 또한, 입력 데이터를 작은 청크로 나누어 각 청크에 대해 Attention을 계산함으로써 메모리 사용량을 줄입니다. 이러한 방식으로, 전체 입력에 대한 한 번의 계산 대신 작은 부분에 대해서만 계산을 수행하여 메모리 사용량을 줄일 수 있습니다.
메모리 최적화 기법
- 연구팀은 또한 메모리 사용을 최적화하기 위해 동적 슬라이싱(dynamic slicing) 및 업데이트 기법을 사용하여, 필요한 부분만 메모리에 로드하고 처리합니다.
- 이러한 접근 방식은 특히 대규모 시퀀스를 처리할 때 메모리 효율성을 크게 향상시킵니다.
결론 및 시사점
- 이 논문의 접근 방식은 셀프 Attention 기반 모델에서의 메모리 사용량 문제를 획기적으로 개선함으로써, 더 긴 시퀀스를 효율적으로 처리할 수 있는 가능성을 열어줍니다.
- 또한, 이 연구는 다양한 아키텍처에 적용될 수 있는 새로운 시각을 제공하며, 향후 연구자들이 모델 설계 시 메모리 효율성을 더욱 고려할 수 있는 계기를 마련합니다.
🤔 논문 리뷰 참여 후기
- 최근 아이펠 코어 그루분들과 Side project로 대용량의 이미지를 학습시키는 모델을 만들고 있는데(약 7TB) 이때 메모리 관련 이슈로 상당히 곤란함을 겪고 있었습니다.
- 그런데 논문을 보면서 솔직히 매우 반가웠습니다. 이 논문에서 제안하는 'Delayed Softmax' 기법이랑, 데이터를 작은 청크로 나눠서 처리하는 방식중에 청크한 데이터를 제너레이터로 넣는 방식을 최근에 적용중이었는데 방향성이 올바르게 되고 있었구나 라는 생각이 들었기 때문입니다.
- 대용량의 데이터 처리라는 점에서 메모리와 용량의 제약으로 한계를 마주한 프로젝트라 난감했었는데 이 논문 덕에 다소 희망을 본 것 같습니다.
Mamba Linear-Time Sequence Modeling with Selective State Spaces
- 솔직히 이 논문에서 제안하는 개념이 워낙 복잡하고 어렵기도하고, 완전히 처음 접해보는 개념이라 이해가 많이 어려웠습니다.
- 세션 이후에 별도로 조금씩 찾아보면서 내용을 이해하려 노력했지만 아직은 좀 부족한듯합니다.
- 그래도 이해한 바에 대해 정리해보자면 아래와 같습니다.
최근 발표된 “Mamba: Linear-Time Sequence Modeling with Selective State Spaces” 논문은 시퀀스 모델링 분야에 새로운 접근 방식을 제시하며, 이 분야의 연구자들에게 큰 관심을 받고 있습니다. 이 논문의 핵심 아이디어와 기술적 내용, 그리고 이것이 시퀀스 모델링 분야에 미치는 영향에 대해 정리해보겠습니다.
문제 정의와 동기
시퀀스 모델링은 자연어 처리(NLP), 음성 인식, 시계열 분석 등 다양한 분야에서 중요한 역할을 합니다. 이러한 문제들에서는 종종 장기 의존성(Long-range dependencies)을 효과적으로 모델링해야 하는 도전과제가 있습니다. 기존의 RNN, LSTM과 같은 모델들은 이러한 장기 의존성을 다루는 데 있어 한계를 보였고, 최근에는 Transformer 기반 모델이 이를 해결하기 위해 널리 사용되고 있습니다. 하지만 Transformer 또한 계산 복잡도와 메모리 사용량 측면에서 제한이 있습니다.
Mamba의 핵심 아이디어

“Mamba” 논문은 선택적 상태 공간 모델(SSSM)을 사용하여 시퀀스 모델링의 이러한 문제를 해결하고자 합니다. SSSM은 전통적인 상태 공간 모델(State Space Model, SSM)을 기반으로 하면서, 모델의 학습과 추론 과정에서 필요한 계산을 효율적으로 수행할 수 있도록 설계되었습니다. 특히, Mamba는 시퀀스의 각 시점에서 상태 공간의 일부만을 선택적으로 사용함으로써, 계산 효율성을 크게 향상시키는 것이 특징입니다.
리뷰를 도와주신 그루분과 아이펠 퍼실님의 설명에 의하면 MAMBA의 SSSM은 제어공학의 SSM에서 출발한 기술이라고 합니다.
-
제어 공학이란?: 제어 공학은 시스템의 동적인 행동을 제어하기 위한 원리와 방법을 연구하는 공학 분야입니다. 이 분야는 시스템이 원하는 대로 작동하도록 입력을 조절하는 기술을 다룹니다. 예를 들어, 자동차의 속도 제어, 로봇의 움직임 제어, 온도 조절 시스템 등이 제어 공학의 적용 예입니다.
-
상태 공간 모델(SSM)이란?: SSM은 시스템의 현재 상태를 기반으로 미래 상태를 예측하고, 시스템의 입력과 출력 사이의 관계를 모델링하는 방법입니다. SSM은 시스템의 동적인 특성을 상태 변수를 통해 수학적으로 표현하며, 이를 통해 시스템의 행동을 분석하고 제어할 수 있습니다.
-
제어 공학에서 SSM의 사용: 제어 공학에서 SSM은 시스템의 제어 및 예측에 중요한 도구로 사용됩니다. SSM을 사용함으로써, 제어 엔지니어는 시스템의 다양한 동적 행동을 정확하게 모델링하고, 이를 바탕으로 시스템을 효과적으로 제어할 수 있는 전략을 개발할 수 있습니다. 예를 들어, 항공기의 비행 제어 시스템에서는 SSM을 사용하여 항공기의 동적 행동을 모델링하고, 이를 통해 항공기가 안정적으로 비행할 수 있도록 제어합니다.
-
SSM에서 MAMBA로의 발전: MAMBA는 SSM의 개념을 기반으로 하면서, 계산 효율성을 극대화하기 위해 선택적 상태 공간을 사용하는 새로운 접근 방식을 제안합니다. 이는 제어 공학에서 시작된 SSM의 기본 원리를 시퀀스 모델링이라는 새로운 문맥에서 확장하고, 특히 대규모 데이터를 효과적으로 처리할 수 있도록 설계되었습니다. MAMBA의 이러한 접근 방식은 시퀀스 데이터의 장기 의존성 문제를 해결하고, 계산 효율성을 높이는 데 중요한 기여를 합니다.
기술적 접근 방식
Mamba 모델은 크게 두 부분으로 구성됩니다. 첫 번째는 선형 시간에 동작하는 컨볼루션 연산을 사용하여 장기 의존성을 모델링하는 부분입니다. 이를 위해 논문에서는 푸리에 변환을 활용한 효율적인 컨볼루션 기법을 제시합니다. 두 번째 부분은 선택적 상태 공간을 통해 모델의 계산 복잡도를 줄이는 방법입니다. 이는 모델이 시퀀스의 각 시점에서 필요한 정보만을 선택적으로 처리할 수 있도록 하여, 불필요한 계산을 줄이고 메모리 사용량을 최적화합니다.
-
S4 모델의 기본 원리: S4 모델은 장기 의존성을 모델링하기 위해 구조화된 상태 공간 모델을 사용합니다. 이 모델은 시퀀스 데이터에서 장기간에 걸친 패턴과 의존성을 효과적으로 학습할 수 있도록 설계되었습니다. 특히, S4는 선형 시간 복잡도를 가진 컨볼루션 연산을 통해 장기 의존성을 처리합니다.
-
MAMBA의 접근 방식: MAMBA는 선택적 상태 공간 모델(SSSM)을 사용하여 계산 효율성을 크게 향상시킵니다. 각 시퀀스 포인트에서 필요한 상태 공간의 일부만을 선택적으로 사용함으로써, 불필요한 계산을 줄이고 메모리 사용을 최적화합니다.
-
결합된 접근 방식: S4와 MAMBA를 결합함으로써, 두 모델의 장점을 통합할 수 있습니다. S4 모델의 장기 의존성 모델링 능력과 MAMBA의 계산 효율성 및 메모리 최적화 기능이 결합되어, 시퀀스 모델링에서의 장기 의존성 문제를 더욱 효과적으로 해결할 수 있습니다. 이를 통해 모델은 더 긴 시퀀스를 더 빠르게 처리하면서도, 필요한 정보만을 효율적으로 처리할 수 있게 됩니다.
실제 적용과 영향
Mamba는 다양한 벤치마크 데이터셋에서 우수한 성능을 보였습니다. 특히 장기 의존성이 중요한 시퀀스 모델링 작업에서 기존 모델들보다 뛰어난 결과를 달성하며, 모델의 효율성과 정확도 사이의 균형을 잘 맞추고 있음을 보여줍니다. Mamba의 접근 방식은 향후 시퀀스 모델링 뿐만 아니라 다양한 딥러닝 모델의 설계에 영향을 미칠 것으로 기대됩니다.
🤔 논문 리뷰 참여 후기
- 발표자 분도 하면서 멘붕이 오셨다고 했는데, 실제로 저는 듣기만 하는데도 멘붕이 오는 느낌이었습니다.
- 처음에는 SSM과 S4 모델에 대해 들었을 때, ‘이게 대체 무슨 소리지?’ 싶었는데, 차근차근 설명을 들어보니 조금씩 이해가 되기 시작했습니다.
- 특히, SSM이 제어공학에서부터 시작된 개념이라는 걸 알고 나니, 딥러닝에 접목시킨 이 새로운 시도가 조금은 흥미롭게 느껴졌습니다. (그렇다고 제어공학이 뭔지 안다는건 아닙니다😂)
- 그저 도메인 지식을 알고리즘화 했다는 점에서 굉장히 흥미롭다고 생각했습니다. 그도 그럴 것이 보통의 머신러닝 모델에는 데이터 부분이든, 기술 적용 부분에서든 도메인 지식에 많은 도움을 받는데 딥러닝은 대용량의 데이터와 알고리즘적 접근 방식으로 그런걸 해결한다고 생각했는데 새로운 접근방식을 본 것 같았기 때문입니다.
- 그리고 맘바(MAMBA)에 대한 소개까지 듣고 나니, ‘아, 이게 다 연결되는 구나’ 싶었습니다. S4와 맘바를 통해 장기 의존성(Long-range dependencies) 문제를 해결하려는 시도가 얼마나 창의적인지 좀 이해가 되는 것 같았습니다.
- 특히, S4 모델이 어떻게 시퀀스 모델링 문제에 접근하고 있는지, 그리고 그것이 기존의 Transformer 모델과 어떻게 다른지를 보면서 조금은 논문의 흐름에 대해 이해가 되는 느낌이었습니다.
- 솔직히 대략적인 부분은 알겠지만, 아직도 이해가 안 되는 부분이 많아서, 다시 한 번 논문을 찾아보고, 추가로 공부를 더 해봐야겠다는 생각이 듭니다.
- 특히, S4 모델의 수학적 기반과, 그것이 실제로 어떻게 롱레인지 디펜던시를 해결할 수 있는지에 대해 많이 공부를 해야 제대로 이 내용을 이해할 수 있겠다 싶습니다.
😀Closing
- 전반적으로 이번 리뷰 세션을 통해 새로운 지식을 많이 배웠고, 앞으로 이 분야에 대해 더 공부해보고 싶다는 동기 부여가 되었습니다.
- 솔직히 다소 어렵고 복잡한 내용이었지만, 그만큼 배울 것이 많은 분야라는 걸 다시 한 번 느꼈습니다.
- 특히, 아이펠톤에서 적용하고 싶은 여러 알고리즘을 찾았다는거는 매우 긍정적인 효과가 아니었나 싶습니다.





댓글남기기